Deepfake: Ancaman Internet Terkini
Aizan Fahri
Berikutan tularnya kandungan palsu di laman sosial Instagram yang memaparkan video pengasas Facebook Mark Zuckerberg melakukan pengumuman yang ganjil berkenaan data yang dimiliki oleh syarikatnya, kami terpanggil untuk hadir dengan rencana bagi memberikan penjelasan apakah yang berlaku dan bagaimana kandungan palsu seperti tersebut berpotensi untuk meruntuhkan integriti masyarakat kita.
Kandungan video berkenaan merupakan salah satu contoh ancaman terkini di internet di mana wajah dan mimik muka seseorang boleh dimanipulasikan dengan menggunakan teknologi terkini pembelajaran mesin (machine learning). Akibatnya, teknologi ini memberikan akses bagi pihak termasuk yang berniat jahat untuk menyebarkan video palsu bagi menjatuhkan individu ataupun institusi tertentu.
Berikutan dengan peristiwa yang berlaku di halaman sosial Reddit pada akhir tahun 2017 di mana kandungan video palsu yang dijana dengan pembelajaran mesin meningkat secara mendadak, kandungan seperti ini menerima nama gelaran “deepfake” yang merupakan gabungan perkataan deep learning dan fake. Kami akan kupaskan peristiwa ini selanjutnya di dalam rencana ini.
Kami ingin menegaskan kepada pembaca sekalian agar menghindari daripada menulis komen yang berbaur politik. Tujuan artikel ini diterbitkan adalah untuk menggalakkan perbincangan ilmiah berkaitan teknik deepfake khususnya dan teknologi pembelajaran mesin amnya. Sebarang komen yang tidak menambah nilai pada rencana ini tidak akan dipaparkan bagi menggalakkan perbincangan yang bermanfaat.
Sejarah Hitam Deepfake
Sama seperti teknologi sebelum ini yang telah disalahguna untuk menyemai kekeliruan di kalangan masyarakat kita seperti penggunaan perisian penyunting imej Adobe Photoshop untuk menjana imej palsu, teknologi di belakang deepfake awalnya dibangunkan untuk kegunaan profesional, contohnya untuk industri perfileman. Sebelum istilah deepfake mula menjadi popular, teknologi ini lebih dikenali sebagai teknologi penukaran wajah (face-swapping). Malah, teknologi face-swapping ini bukanlah teknologi yang asing. Rata-rata di antara kita pasti sudah mencuba penapis (filter) pada aplikasi Instagram dan Snapchat, contohnya untuk menjana wajah perempuan pada lelaki dan juga untuk menjana animoji.
Seiring dengan perkembangan teknologi pembelajaran mesin dan keterdapatan perisian sumber terbuka untuk melakukan proses pengecaman dan penukaran wajah, teknik ini semakin mudah untuk diakses oleh pengguna biasa dan statusnya bukan lagi unik untuk industri besar. Hal ini membuka peluang yang luas bagi individu yang berminat dengan teknologi penglihatan komputer (computer vision) untuk membangunkan perisian dan teknik baharu.
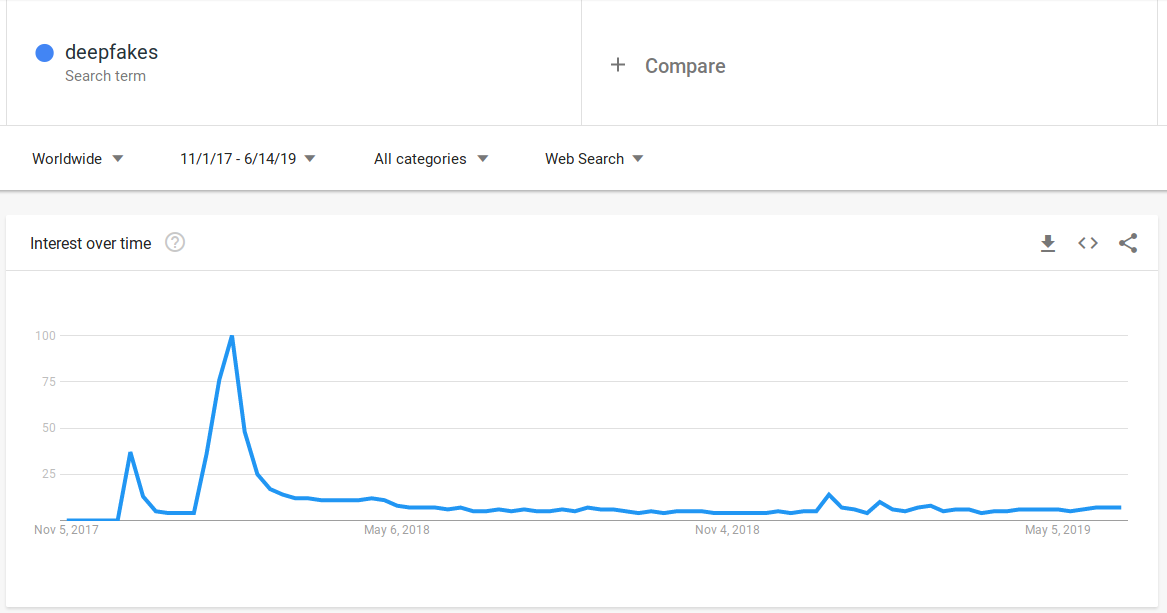
Landskap penjanaan kandungan video palsu mula menjadi-jadi pada akhir tahun 2017 dan ia bermula di halaman sosial Reddit. Satu akaun pengguna Reddit dengan ID /u/deepfakes beserta beberapa individu lain di komuniti subreddit /r/deepfakes mula memuat naik kandungan video pornografi palsu. Berdasarkan laporan media, individu-individu yang terlibat dengan pengeluaran dan penyebaran video pornografi palsu menggunakan wajah selebriti antarabangsa yang terkenal seperti Gal Gadot dengan mencantumkan muka beliau pada aktres pornografi yang sedang melakukan aksi ranjang.
Pada awal tahun 2018, laporan media antarabangsa mula memberi perhatian kepada aktiviti penyebaran kandungan pornografi palsu yang kian menular bukan sahaja di kalangan ahli komuniti /r/deepfakes tetapi di laman sosial yang lain termasuklah Twitter. Ketika ini, istilah deepfakes meningkat secara mendadak di laman carian Google, membawa kepada penggunaan istilah deepfake yang membawa konotasi negatif penyebaran kandungan lucah yang dijana secara sintetik menggunakan teknologi pembelajaran mesin.
Teknologi Di Sebalik Deepfake
Ingin kami maklumkan bahawa perbincangan berkisar di sebalik teknologi deepfake adalah mustahil dilakukan tanpa menyelam jauh ke dalam bidang ilmu sains perkomputeran, lebih-lebih lagi bidang pembelajaran mesin yang sarat dengan istilah dan teori matematik. Bagi rencana siri ini, kami ingin membawakan kepada anda konsep asas proses penjanaan kandungan deepfake. Ingin kami ingatkan kepada para pembaca bahawa penjelasan yang kami bawakan kali ini ditulis dalam bahasa yang mudah dan mungkin tidak mencerminkan realiti teknologi ini yang rumit dan kompleks.

Pertama sekali, proses penjanaan ini merupakan proses yang memerlukan sumber intensif (resource intensive), seperti kad grafik (GPU) dan unit pemprosesan pusat (CPU) yang berkuasa tinggi.
Amnya, proses penjanaan ini memerlukan sekurang-kurang CPU 4 teras dan ke atas dengan kelajuan jam (clock speed) 3.5 GHz atau lebih tinggi. Bagi GPU pula, kad grafik Nvidia lazimnya menjadi pilihan kerana perpustakaan perisian (software library) General Purpose Graphic Processing Unit (GPGPU) CUDA oleh Nvidia lebih matang dan mempunyai sokongan yang lebih meluas berbanding perpustakaan perisian ROCm yang dikeluarkan oleh AMD bagi siri kad grafik Radeon mereka. Dari sudut spesifikasi bagi melakukan proses penjanaan yang efisien, kad grafik tersebut mestilah mempunyai VRAM 6GB dan ke atas.
Ringkasnya, proses penjanaan ini memerlukan kepada sekurang-kurangnya kad grafik Nvidia GTX 1070 dan kebiasaannya pengguna disyorkan untuk menggunakan kad grafik Nvidia GTX 1080. Bagi jumlah RAM yang diperlukan pula, amnya jumlah RAM 8 GB dan ke atas diperlukan bagi proses penjanaan yang efisien. Melihat kepada spesifikasi perkakasan sahaja, proses penjanaan ini bukanlah proses yang berkos rendah.

Dengan anggapan bahawa perkakasan yang diperlukan sedia untuk digunakan dan semua perpustakaan perisian seperti TensorFlow, CUDA, dan cuDNN telah dipasang dengan betul, maka proses penjanaan boleh dimulakan.
Proses ini terbahagi kepada 3 bahagian: pengekstrakan (extraction), latihan (training), dan penjanaan (generation). Kebiasaannya, proses yang kedua iaitu latihan merupakan proses yang mengambil masa paling panjang berdasarkan anggapan jika anda sudah mempunyai fail-fail gambar dalam jumlah yang besar.
Proses kedua iaitu proses melatih model pembelajaran mesin (machine learning model) merupakan satu konsep yang kompleks dan sukar untuk dijelaskan. Kami memerlukan satu rencana khas untuk memberikan penjelasan yang lengkap bagaimanakah proses ini dilakukan, mungkin pada masa akan datang. Buat sementara waktu, penjelasan mudah yang boleh kami berikan ialah proses latihan ini akan membawa kepada penghasilan data ramalan yang boleh membantu langkah ketiga iaitu proses penjanaan.
Sebagai contoh yang kasar, andaikan situasi di mana kami berminat untuk menjana wajah Scarlett Johansson secara sintetik untuk menghasilkan wajah baru yang seakan-akan orang Asia. Bagi mencapai matlamat ini, kami menggunakan wajahnya dari filem Avengers: Civil War sebagai sumber fail untuk menghasilkan model pembelajaran machine. Kemudian, untuk mengadaptasikan ciri-ciri wajah orang Asia, kami menggunakan wajah pelakon dari Cina, Jing Tian, sebagai sumber kedua bagi model pembelajaran mesin untuk mempelajari dan menilai ciri-ciri wajah orang Asia.
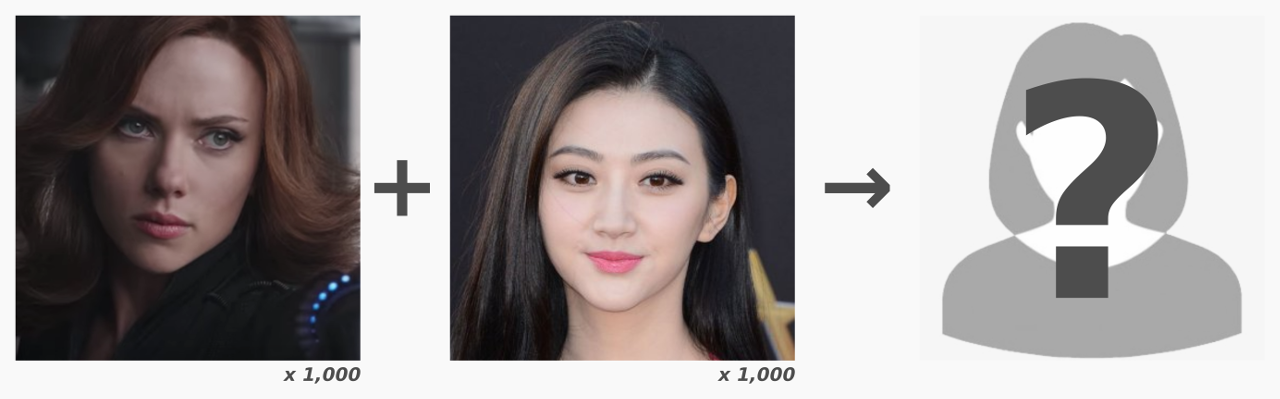
Proses yang dinyatakan di atas merupakan sebahagian daripada langkah pengekstrakan. Langkah ini memerlukan kepada sumber gambar pada jumlah yang besar (ratusan ataupun ribuan gambar, sebagai contoh). Algoritma tertentu kemudiannya digunakan untuk melakukan pengecaman wajah dan pengekstrakan ciri-ciri wajah untuk “disuap” ke dalam model pembelajaran mesin untuk memulakan proses latihan.
Proses ini mungkin mengambil masa berjam-jam dan tidak mustahil boleh melangkau sehingga beberapa hari untuk selesai, bergantung kepada kebolehan perkakasan anda dan jumlah fail-fail sumber yang digunakan.
Apa yang berlaku dalam proses latihan ini ialah sistem pembelajaran mesin akan meneliti setiap pixel pada semua gambar yang telah diekstrak dan mula melakukan proses penukaran wajah secara beransur-ansur, langkah demi langkah, bit demi bit. Setiap kitaran yang berlaku mempunyai proses maklum-balas (feedback) bagi membolehkan algoritma pembelajaran mesin untuk melakukan penambahbaikan kepada proses penukaran wajah.
Natijahnya, model pembelajaran mesin mempunyai data ramalan yang mungkin mencukupi untuk mula melakukan penjanaan sintetik untuk menghasilkan wajah Scarlett Johansson dengan ciri-ciri wajah orang Asia.

Ingin kami nyatakan bahawa analogi ini menggunakan imej pegun (still images). Untuk mengelakkan kecelaruan informasi berlaku, teknik deepfake lebih merujuk kepada gambar bergerak (moving pictures) seperti kandungan video. Kami berharap penjelasan ini boleh memberi gambaran mengapa proses ini memerlukan kepada perkakasan berkuasa tinggi dan masa yang lama untuk melengkapkan proses penjanaan. Tidak mustahil teknik deepfake boleh digunakan untuk menghasilkan video Keanu Reeves atau Elon Musk membuat pengumuman hari raya menggantikan penyimpan mohor-mohor besar diraja.
Dalam erti kata lain juga, jika gambar-gambar anda boleh didapati dengan senang di atas talian dalam jumlah yang besar, terdapat kebarangkalian anda mungkin terdedah kepada ancaman deepfake. Jaga-jaga sebelum berkongsi.
Membendung Penularan: Fikir Dahulu Sebelum Kongsi
Menelurusi kehidupan dalam era yang dipenuhi dengan fitnah yang merebak dengan berleluasa, setiap anggota masyarakat yang mempunyai akses kepada informasi di internet mempunyai tanggungjawab besar.
Perkara pertama yang perlu kita kenali ialah bukan semua kandungan yang tersebar di internet sah dari sudut fakta dan kebenaran. Kita mesti sedar bahawa terdapat anasir jahat dengan agenda untuk menyebarkan kandungan bertujuan untuk memanipulasikan sentimen dalam masyarakat.
Perkara penting yang kedua ialah setiap perkongsian yang kita lakukan di alam maya mestilah dilakukan secara bertanggungjawab. Setiap kali sebelum anda ingin menyebarkan kandungan di internet, anda perlu bertanyakan kepada diri sendiri soalan-soalan ini: (1) adakah aku melakukan penyebaran kandungan ini secara bertanggungjawab; (2) jika aku salah, siapakah yang akan terjejas; (3) kepada siapakah aku patut bertanyakan soalan sekiranya pemahaman aku salah. Jika anda menggunakan 3 soalan ini sebagai formula, kehidupan kita di alam maya mungkin akan lebih terjaga, sihat, dan sejahtera.
Lakukan penyebaran secara bertanggungjawab dan amalkan perkongsian kandungan yang sihat.